
The Proof of Learning in Machine Learning/AI | by Rômulo Pauliv | May, 2024
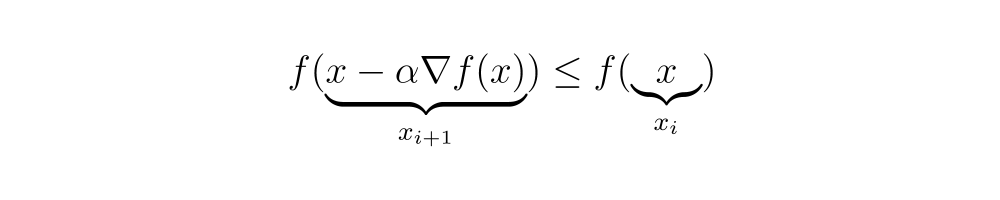
[ad_1]
This algorithm is known as “Gradient Descent” or “Method of Steepest Descent,” being an optimization method to find the minimum of a function where each step is taken in the direction of the negative gradient. This method does not guarantee that the global minimum of the function will be found, but rather a local minimum.
Discussions about finding the global minimum could be developed in another article, but here, we have mathematically demonstrated how the gradient can be used for this purpose.
Now, applying it to the cost function E that depends on the n weights w, we have:

To update all elements of W based on gradient descent, we have:

And for any nth element 𝑤 of the vector W, we have:

Therefore, we have our theoretical learning algorithm. Logically, this is not applied to the hypothetical idea of the cook, but rather to numerous machine learning algorithms that we know today.
Based on what we have seen, we can conclude the demonstration and the mathematical proof of the theoretical learning algorithm. Such a structure is applied to numerous learning methods such as AdaGrad, Adam, and Stochastic Gradient Descent (SGD).
This method does not guarantee finding the n-weight values w where the cost function yields a result of zero or very close to it. However, it assures us that a local minimum of the cost function will be found.
To address the issue of local minima, there are several more robust methods, such as SGD and Adam, which are commonly used in deep learning.
Nevertheless, understanding the structure and the mathematical proof of the theoretical learning algorithm based on gradient descent will facilitate the comprehension of more complex algorithms.
References
Carreira-Perpinan, M. A., & Hinton, G. E. (2005). On contrastive divergence learning. In R. G. Cowell & Z. Ghahramani (Eds.), Artificial Intelligence and Statistics, 2005. (pp. 33–41). Fort Lauderdale, FL: Society for Artificial Intelligence and Statistics.
García Cabello, J. Mathematical Neural Networks. Axioms 2022, 11, 80.
Geoffrey E. Hinton, Simon Osindero, Yee-Whye Teh. A Fast Learning Algorithm for Deep Belief Nets. Neural Computation 18, 1527–1554. Massachusetts Institute of Technology
LeCun, Y., Bottou, L., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278–2324.
[ad_2]



