
Building an efficient MLOps platform with OSS tools on Amazon ECS with AWS Fargate
[ad_1]
This post has been co-written with Artem Sysuev, Danny Portman, Matúš Chládek, and Saurabh Gupta from Zeta Global.
Zeta Global is a leading data-driven, cloud-based marketing technology company that empowers enterprises to acquire, grow and retain customers. The company’s Zeta Marketing Platform (ZMP) is the largest omnichannel marketing platform with identity data at its core. The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. For more information, see Zeta Global’s home page.
What Zeta has accomplished in AI/ML
In the fast-evolving landscape of digital marketing, Zeta Global stands out with its groundbreaking advancements in artificial intelligence. Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deep learning and generative AI to marketing technology. Using AI, Zeta Global has revolutionized how brands connect with their audiences, offering solutions that aren’t just innovative, but also incredibly effective. As an early adopter of large language model (LLM) technology, Zeta released Email Subject Line Generation in 2021. This tool enables marketers to craft compelling email subject lines that significantly boost open rates and engagement, tailored perfectly to the audience’s preferences and behaviors.
Further expanding the capabilities of AI in marketing, Zeta Global has developed AI Lookalikes. This technology allows companies to identify and target new customers who closely resemble their best existing customers, thereby optimizing marketing efforts and improving their return on investment (ROI). The backbone of these advancements is ZOE, Zeta’s Optimization Engine. ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation. Together, these AI-driven tools and technologies aren’t just reshaping how brands perform marketing tasks; they’re setting new benchmarks for what’s possible in customer engagement.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently.
Zeta’s AI innovation is powered by a proprietary machine learning operations (MLOps) system, developed in-house.
Context
In early 2023, Zeta’s machine learning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets. This paradigm shift aimed to accelerate project delivery by fostering collaboration and synergy among teams with varied expertise. The need for a centralized MLOps platform became apparent as ML and AI applications proliferated across various teams, leading to a maze of maintenance complexities and hindering knowledge transfer and innovation.
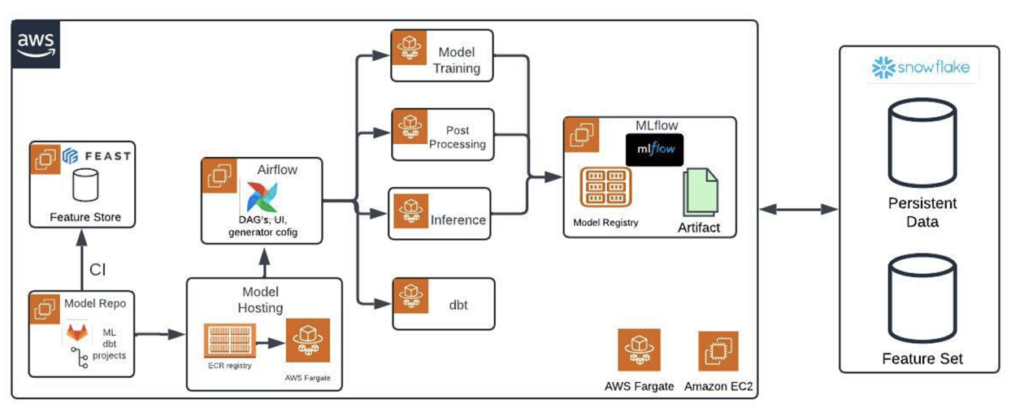
To address these challenges, the organization developed an MLOps platform based on four key open-source tools: Airflow, Feast, dbt, and MLflow. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
Architecture overview
Our MLOps architecture is designed to automate and monitor all stages of the ML lifecycle. At its core, it integrates:
- Airflow for workflow orchestration
- Feast for feature management
- dbt for accelerated data transformation
- MLflow for experiment tracking and model management
These components interact within the Amazon ECS environment, providing a scalable and serverless platform where ML workflows are run in containers using Fargate. This setup not only simplifies infrastructure management, but also ensures that resources are used efficiently, scaling up or down as needed.
The following figure shows the MLOps architecture.

Architectural deep dive
The following details dive deep into each of the components used in this architecture.
Airflow for workflow orchestration
Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks. Every Airflow task calls Amazon ECS tasks with some overrides. Additionally, we’re using a custom Airflow operator called ECSTaskLogOperator that allows us to process Amazon CloudWatch logs using downstream systems.
Feast for feature management
Feast acts as a central repository for storing and serving features, ensuring that models in both training and production environments use consistent and up-to-date data. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
dbt for data transformation
dbt is used for transforming data within the data warehouse, allowing data teams to define complex data models in SQL. It promotes a disciplined approach to data modeling, making it easier to ensure data quality and consistency across the ML pipelines. Moreover, it provides a straightforward way to track data lineage, so we can foresee which datasets will be affected by newly introduced changes. The following figure shows schema definition and model which reference it.

MLflow for experiment tracking and model management
MLflow tracks experiments and manages models. It provides a unified interface for logging parameters, code versions, metrics, and artifacts, making it easier to compare experiments and manage the model lifecycle.
Similarly to Airflow, MLflow is also used just partially. The main parts we use are tracking the server and model registry. From our experience, artifact server has some limitations, such as limits on artifact size (because of sending it using REST API). As a result, we opted to use it only partially.
We don’t extensively use the deployment capabilities of MLflow, because in our current setup, we build custom inference containers.
Hosting on Amazon ECS with Fargate
Amazon ECS offers a highly scalable and secure environment for running containerized applications. Fargate eliminates the need for managing underlying infrastructure, allowing us to focus solely on deploying and running the containers. This abstraction layer simplifies the deployment process, enabling seamless scaling based on workload demands while optimizing resource utilization and cost efficiency.
We found it optimal to run on Fargate components of our ML workflows that don’t require GPUs or distributed processing. These include dbt pipelines, data gathering jobs, training, evaluation, and batch inference jobs for smaller models.
Furthermore, Amazon ECS and Fargate seamlessly integrate with other AWS services, such as Amazon Elastic Container Registry (Amazon ECR) for container image management and AWS Systems Manager Parameter Store for securely storing and managing secrets and configurations. Using Parameter Store, we can centralize configuration settings, such as database connection strings, API keys, and environment variables, eliminating the need for hardcoding sensitive information within container images. This enhances security and simplifies maintenance, because secrets and configuration values can be dynamically retrieved by containers at runtime, ensuring consistency across deployments.
Moreover, integrating Amazon ECS and Fargate with CloudWatch enables comprehensive monitoring and logging capabilities for containerized tasks. This can be achieved by enabling the awslogs log driver within the logConfiguration parameters of the task definitions.
Why ECS with Fargate is the solution of choice
- Serverless model:
-
- No infrastructure management: With Fargate, we don’t need to provision, configure, or manage servers. This simplifies operations and reduces the operational overhead, allowing teams to focus on developing and deploying applications.
- Automatic scaling: Fargate automatically scales our applications based on demand, ensuring optimal performance without manual intervention.
- Cost efficiency:
-
- Pay-as-we-go: Fargate charges are based on the resources (vCPU and memory) that the containers use. This model can be more cost-effective compared to maintaining idle resources.
- No over provisioning: Because we only pay for what we use, there’s no need to over-provision resources, which can lead to cost savings.
- Enhanced security:
-
- Isolation: Each Fargate task runs in its own isolated environment, improving security. There’s no sharing of underlying compute resources with other tenants.
- Integration with the AWS ecosystem:
Configuring Amazon ECS with Fargate for ML workloads
Configuring Amazon ECS with Fargate for ML workloads involves the following steps.
- Docker images: ML models and applications are containerized using Docker. This includes all dependencies, libraries, and configurations needed to run the ML workload.
- Creating task definitions:
-
- Define resources: Create an Amazon ECS task definition specifying the Docker image, required vCPU, memory, and other configurations.
- Environment variables: Set environment variables, such as model paths, API keys, and other necessary parameters.
- IAM roles: Assign appropriate AWS Identity and Access Management (IAM) roles to the tasks for accessing other AWS resources securely.
- Logging using CloudWatch: Use CloudWatch for logging and monitoring the performance and health of ML workloads.
Future development and addressing emerging challenges
As the field of MLOps continues to evolve, it’s essential to anticipate and address upcoming challenges to ensure that the platform remains efficient, scalable, and user-friendly. Two primary areas of future development for our platform include:
- Enhancing bring your own model (BYOM) capabilities for external clients
- Reducing the learning curve for data scientists
This section outlines those challenges and proposes directions for future enhancements.
Enhancing BYOM capabilities
As machine learning becomes more democratized, there is a growing need for platforms to easily integrate models developed externally by Zeta’s clients.
Future directions:
- Developing standardized APIs: Implement APIs that allow for easy integration of external models, regardless of the framework or language they were developed in. This would involve creating a set of standardized interfaces for model ingestion, validation, and deployment.
- Creating a model adapter framework: Design a framework that can adapt external models to be compatible with the platform’s infrastructure, ensuring that they can be managed, tracked, and deployed just like internally developed models.
- Enhancing documentation and support: Provide comprehensive documentation and support resources to guide external clients through the BYOM process, including best practices for model preparation, integration, and optimization.
Reducing the learning curve for data scientists
The incorporation of multiple specialized tools (Airflow, Feast, dbt, and MLflow) into the MLOps pipeline can present a steep learning curve for data scientists, potentially hindering their productivity and the overall efficiency of the ML development process.
Future directions:
We’ll do the following to help reduce the learning curve:
- Creating unified interfaces: Develop a unified interface, including UI, API, and SDK, that abstracts away the complexities of interacting with each tool individually. This interface could provide simplified workflows, automating routine tasks and presenting a cohesive view of the entire ML lifecycle.
- Offering comprehensive training and resources: Invest in training programs and resources tailored to data scientists at different skill levels. This could include interactive tutorials, workshops, and detailed case studies showcasing real-world applications of the platform.
Conclusion
Integrating Airflow, Feast, dbt, and MLflow into an MLOps platform hosted on Amazon ECS with AWS Fargate presents a robust solution for managing the ML lifecycle. This setup not only streamlines operations but also enhances scalability and efficiency, allowing data science teams to focus on innovation rather than infrastructure management.
Additional Resources
For those looking to dive deeper, we recommend exploring the official documentation and tutorials for each tool: Airflow, Feast, dbt, MLflow) and Amazon ECS. These resources are invaluable for understanding the capabilities and configurations of each component in our MLOps platform.
About the authors
 Varad Ram holds the position of Senior Solutions Architect at Amazon Web Services. He possesses extensive experience encompassing application development, cloud migration strategies, and information technology team management. Recently, his primary focus has shifted towards assisting clients in navigating the process of productizing generative artificial intelligence use cases.
Varad Ram holds the position of Senior Solutions Architect at Amazon Web Services. He possesses extensive experience encompassing application development, cloud migration strategies, and information technology team management. Recently, his primary focus has shifted towards assisting clients in navigating the process of productizing generative artificial intelligence use cases.
 Artem Sysuev is a Lead Machine Learning Engineer at Zeta, passionate about creating efficient, scalable solutions. He believes that effective processes are key to success, which led him to focus on both machine learning and MLOps. Starting with machine learning, Artem developed skills in building predictive models. Over time, he saw the need for strong operational frameworks to deploy and maintain these models at scale, which drew him to MLOps. At Zeta, he drives innovation by automating workflows and improving collaboration, ensuring smooth integration of machine learning models into production systems.
Artem Sysuev is a Lead Machine Learning Engineer at Zeta, passionate about creating efficient, scalable solutions. He believes that effective processes are key to success, which led him to focus on both machine learning and MLOps. Starting with machine learning, Artem developed skills in building predictive models. Over time, he saw the need for strong operational frameworks to deploy and maintain these models at scale, which drew him to MLOps. At Zeta, he drives innovation by automating workflows and improving collaboration, ensuring smooth integration of machine learning models into production systems.
 Saurabh Gupta is a Principal Engineer at Zeta Global. He is passionate about machine learning engineering, distributed systems, and big-data technologies. He has built scalable platforms that empower data scientists and data engineers, focusing on low-latency, resilient systems that streamline workflows and drive innovation. He holds a B.Tech degree in Electronics and Communication Engineering from the Indian Institute of Technology (IIT), Guwahati, and has deep expertise in designing data-driven solutions that support advanced analytics and machine learning initiatives.
Saurabh Gupta is a Principal Engineer at Zeta Global. He is passionate about machine learning engineering, distributed systems, and big-data technologies. He has built scalable platforms that empower data scientists and data engineers, focusing on low-latency, resilient systems that streamline workflows and drive innovation. He holds a B.Tech degree in Electronics and Communication Engineering from the Indian Institute of Technology (IIT), Guwahati, and has deep expertise in designing data-driven solutions that support advanced analytics and machine learning initiatives.
 Matúš Chládek is a Senior Engineering Manager for ML Ops at Zeta Global. With a career that began in Data Science, Matúš has developed a strong foundation in analytics and machine learning. Over the years, Matúš transitioned into more engineering-focused roles, eventually becoming a Machine Learning Engineer before moving into Engineering Management. Matúš’s leadership focuses on building robust, scalable infrastructure that streamlines workflows and supports rapid iteration and production-ready delivery of machine learning projects. Matúš is passionate about driving innovation at the intersection of Data Science and Engineering, making advanced analytics accessible and scalable for internal users and clients alike.
Matúš Chládek is a Senior Engineering Manager for ML Ops at Zeta Global. With a career that began in Data Science, Matúš has developed a strong foundation in analytics and machine learning. Over the years, Matúš transitioned into more engineering-focused roles, eventually becoming a Machine Learning Engineer before moving into Engineering Management. Matúš’s leadership focuses on building robust, scalable infrastructure that streamlines workflows and supports rapid iteration and production-ready delivery of machine learning projects. Matúš is passionate about driving innovation at the intersection of Data Science and Engineering, making advanced analytics accessible and scalable for internal users and clients alike.
 Dr. Danny Portman is a recognized thought leader in AI and machine learning, with over 30 patents focused on Deep Learning and Generative AI applications in advertising and marketing technology. He holds a Ph.D. in Computational Physics, specializing in high-performance computing models for simulating complex astrophysical systems. With a strong background in quantitative research, Danny brings a wealth of experience in applying data-driven approaches to solve problems across various sectors. As VP of Data Science and Head of AI/ML at Zeta Global, Dr. Portman leads the development of AI-driven products and strategies, and spearheads the company’s cutting-edge Generative AI R&D efforts to deliver innovative solutions for marketers.
Dr. Danny Portman is a recognized thought leader in AI and machine learning, with over 30 patents focused on Deep Learning and Generative AI applications in advertising and marketing technology. He holds a Ph.D. in Computational Physics, specializing in high-performance computing models for simulating complex astrophysical systems. With a strong background in quantitative research, Danny brings a wealth of experience in applying data-driven approaches to solve problems across various sectors. As VP of Data Science and Head of AI/ML at Zeta Global, Dr. Portman leads the development of AI-driven products and strategies, and spearheads the company’s cutting-edge Generative AI R&D efforts to deliver innovative solutions for marketers.
[ad_2]



