

Racing into the future: How AWS DeepRacer fueled my AI and ML journey
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer—a fully autonomous 1/18th scale...
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer—a fully autonomous 1/18th scale...

As artificial intelligence advances, training large-scale neural networks, including large language models, has become increasingly critical. The growing size and...

Cloud technologies are progressing at a rapid pace. Businesses are adopting new innovations and technologies to create cutting-edge solutions for...

How paying “better” attention can drive ML cost savingsPhoto by Andrew Seaman on UnsplashIntroduced in the landmark 2017 paper “Attention...

Today, we are happy to announce the availability of Binary Embeddings for Amazon Titan Text Embeddings V2 in Amazon Bedrock...

OpinionData is getting too complicated for Excel to keep upPython is taking over what used to be Excel-dominated terrains. Image...

Principal is a global financial company with nearly 20,000 employees passionate about improving the wealth and well-being of people and...
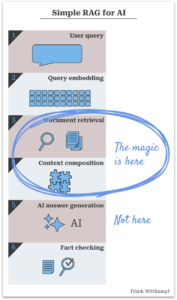
Why retrieval, not generation, makes RAG systems magicalQuick POCsMost quick proof of concepts (POCs) which allow a user to explore...

In the rapidly evolving landscape of AI, generative models have emerged as a transformative technology, empowering users to explore new...

Practical techniques to accelerate heavy workloads with GPU optimization in PythonPhoto by Mathew Schwartz on UnsplashOne of the biggest challenges...

This post is co-written with Mayur Patel, Nick Koenig, and Karthik Jetti from GoDaddy. GoDaddy empowers everyday entrepreneurs by providing...

MODEL VALIDATION & OPTIMIZATIONStop using moving boxes!10 min read·16 hours agoYou know those cross-validation diagrams in every data science tutorial?...

The Cohere Embed multimodal embeddings model is now generally available on Amazon SageMaker JumpStart. This model is the newest Cohere...

|LLM|INTERPRETABILITY|SPARSE AUTOENCODERS|XAI|A deep dive into LLM visualization and interpretation using sparse autoencodersImage created by the author using DALL-EAll things are...

In Part 1 of this series, we defined the Retrieval Augmented Generation (RAG) framework to augment large language models (LLMs)...
