
Elevate RAG for numerical analysis using Amazon Bedrock Knowledge Bases
[ad_1]
In the realm of generative artificial intelligence (AI), Retrieval Augmented Generation (RAG) has emerged as a powerful technique, enabling foundation models (FMs) to use external knowledge sources for enhanced text generation.
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon Bedrock Knowledge Bases is a fully managed capability that helps you implement the entire RAG workflow—from ingestion to retrieval and prompt augmentation—without having to build custom integrations to data sources and manage data flows. However, RAG has had its share of challenges, especially when it comes to using it for numerical analysis. This is the case when you have information embedded in complex nested tables. Latest innovations in Amazon Bedrock Knowledge Base provide a resolution to this issue.
In this post, we explore how Amazon Bedrock Knowledge Bases address the use case of numerical analysis across a number of documents.
The power of RAG and its limitations
With RAG, an information retrieval component is introduced that utilizes the user input to first pull relevant information from a data source. The user query and the relevant information are both given to the large language model (LLM). The LLM uses the new knowledge and its training data to create better responses.
Although this approach holds a lot of promise for textual documents, the presence of non-textual elements, such as tables, pose a significant challenge. One issue is that the table structure by itself can be difficult to interpret when directly queried against documents in PDFs or Word. This can be addressed by transforming the data into a format such as text, markdown, or HTML.
Another issue relates to search, retrieval, and chunking of documents that contain tables. The first step in RAG is to chunk a document so you can transform that chunk of data into a vector for a meaningful representation of text. However, when you apply this method to a table, even if converted into a text format, there is a risk that the vector representation doesn’t capture all the relationships in the table. As a result, when you try to retrieve information, a lot of information is missed. Because this information isn’t retrieved, the LLM doesn’t provide accurate answers to your questions.
Amazon Bedrock Knowledge Bases provide three capabilities to resolve this issue:
- Hybrid search – A hybrid search retrieves information based on semantic meaning through vector representations as well as through keywords. As a result, information on particular key fields that was being missed earlier using purely semantic search is retrieved, and the LLM is able to accurately provide the correct answers. For more information on Amazon Bedrock’s hybrid search capability, see Amazon Bedrock Knowledge Bases now supports hybrid search.
- Chunking data in fixed sizes – You can specify a fixed size for the data that is eventually transformed into a vector. Small sizes imply smaller amounts of data and vice versa.
- Retrieving a large number of chunks from your search results – These are the number of chunks retrieved as the result of your search. The greater the number of results retrieved, the more context provided to the LLM for an answer.
Using a combination of these features can enhance numerical analysis of information across multiple documents that contain data in tables. In the next section, we demonstrate this approach using a set of earnings documents from Amazon.
Solution overview
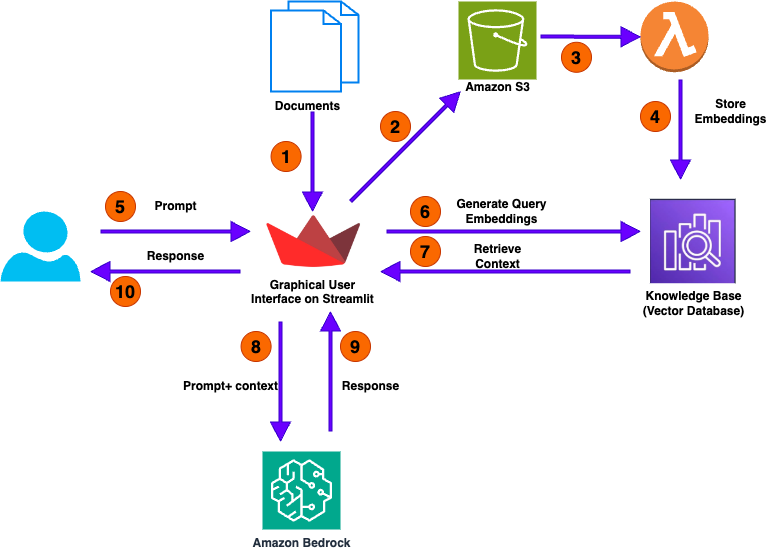
The following diagram illustrates the high-level architecture of our solution for analyzing numerical documents.

The user call flow consists of the following steps:
- The process begins with the user uploading one or more documents. This action initiates the workflow.
- The Streamlit application, which designed to facilitate user interaction, takes these uploaded documents and stores them in an Amazon Simple Storage Service (Amazon S3) bucket.
- After the documents are successfully copied to the S3 bucket, the event automatically invokes an AWS Lambda
- The Lambda function invokes the Amazon Bedrock knowledge base API to extract embeddings—essential data representations—from the uploaded documents. These embeddings are structured information that capture the core features and meanings of the documents.
- With the documents processed and stored, the GUI of the application becomes interactive. Users can now engage with the application by asking questions in natural language through the user-friendly interface.
- When a user submits a question, the application converts this query into query embeddings. These embeddings encapsulate the essence of the user’s question, which helps with retrieving the relevant context from the knowledge base.
- you can use the Retrieve API to query your knowledge base with information retrieved directly from the knowledge base. The RetrieveAndGenerate API uses the retrieved results to augment the foundation model (FM) prompt and returns the response.
- Using a hybrid search method that combines keyword-based and semantic-based techniques, the application searches its knowledge base for relevant information related to the user’s query. This search aims to find contextual answers that match both the explicit terms and the intended meaning of the question.
- When relevant context is identified, the application forwards this information—both the user’s query and the retrieved context—to the LLM module.
- The LLM module processes the provided query and context to generate a response.
- The application delivers the generated response back to the user through its GUI. This completes the loop of interaction, where the user’s initial query results in a comprehensive and contextually relevant response derived from the uploaded documents and the application’s knowledge base.
In the following sections, we walk through the steps to create an S3 bucket and knowledge base, deploy the Streamlit application with AWS CloudFormation, and test the solution.
Prerequisites
You should have the following prerequisites:
- An AWS account with necessary permissions
- Access to launch AWS CloudFormation
- Access to the Anthropic Claude 3 Sonnet and Amazon Titan Text Embeddings v2 models on Amazon Bedrock
- The CloudFormation template downloaded to your local computer
Create an S3 bucket
Complete the following steps to create your S3 bucket:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Choose Create bucket.
- Enter a unique bucket name that follows the S3 bucket naming rules.
- Choose the AWS Region where you want to create the bucket. It is recommended to choose Region that is geographically close to you.
- Leave the other settings at their default values and choose Create bucket.
Create a knowledge base
Complete the following steps to create a knowledge base with default settings:
- On the Amazon Bedrock console, choose Knowledge bases under Builder tools in the navigation pane.
- Choose Create knowledge base.
- In the Provide knowledge base details section, provide the following information:
- In the Choose data source section, select the radio button for Amazon S3 and choose Next
- In the Configure data source section, provide the following information
- For S3 URI, enter the S3 path for the bucket you created.
- For chunking and parsing configurations, select the radio button for Custom
- For Chunking strategy, choose Fixed-size chunking.
- For Max tokens, enter 250.
- For Overlap percentage between chunks, enter 30.
- Leave everything as default and choose Next.

- In the Select embeddings model and configure vector store section, provide the following information:
- For Embeddings model, choose Titan Text Embeddings v2.
- Under Vector database, select Quick create a new vector store.
- Leave everything else as default and choose Next.

- Review the knowledge base settings and choose Create knowledge base.

- Amazon Bedrock will now provision the necessary resources and set up the knowledge base for you as shown in the screen below (Note: This process may take a few minutes to complete). Note the knowledge base ID as shown

- Click on the data source name and note the Data source ID as shown

Create the Streamlit application
After the knowledge base is setup using the above 9 steps, complete the following steps to create the Streamlit application using the CloudFormation template:
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Choose Create stack.
- Select With new resources (standard).
- For the template source, choose Upload a template file.
- Choose Choose file and upload the template you downloaded earlier.
- Enter a name for your stack.
- Configure the following parameters:
- KnowledgeBase Configuration
- For KnowledgeBasedID, enter the knowledge base ID that you saved earlier.
- For DatasourceID, enter the data source ID that you saved earlier.
- S3Bucket Configuration
- For RAGDocumentInput, enter the name of the bucket you created.
- S3Bucket Configuration
- For SubnetId, choose your public subnet
- For VpcId, choose the VPC ID in which you want to deploy the Streamlit application.
- For YourPublicIP, enter the public IP address from where you access the Streamlit application.
- S3Bucket Configuration
- For InstanceType and LatestLinuxAMI, you can use the default values
- KnowledgeBase Configuration
- Review the stack details and select the checkbox in the Capabilities section:
- I acknowledge that AWS CloudFormation might create IAM resources
- Choose Create stack to initiate the stack creation process. This will take few minutes to complete.

When the stack is complete, you can refer to the stack’s Outputs tab for the Streamlit application URL.
Now that we have deployed the Streamlit application, let’s see how users can interact with it and ask questions.
Test the solution
We can divide the UI experience into two phases: document ingestion and document querying.
The document ingestion workflow consists of the following steps:
- Users use the Streamlit application to upload documents. For testing, we can use Amazon earnings for the last 16 quarters. The application then uploads the documents to an S3 bucket.
- The upload event invokes a Lambda function. This function starts the ingestion job to sync the data to the knowledge base. Using the specified chunking strategy, the knowledge base converts the documents in the S3 bucket to vector embeddings, which are stored in the default Amazon OpenSearch serverless vector database. This process will take about 15 minutes to complete. You can follow the steps mentioned here to check the sync history which contains the details about when the data source was synced, Please wait for sync to complete to start asking questions in the streamlit application
The document querying workflow consists of the following steps:
- Users interact with a Streamlit application running on Amazon Elastic Compute Cloud (Amazon EC2 ), where they enter questions (queries) about the documents and receive responses.
- The application passes the queries to the knowledge base.
- The knowledge base returns the most relevant text. In this case, because we’re using hybrid search, it returns keyword-based as well as semantic search-based results. In the hybrid search, we maximize the number of chunks returned (to 100).
- The application invokes the specified LLM in Amazon Bedrock and passes the retrieved results as context, along with the original query, to the LLM.
- The LLM model processes the prompts and context, and returns responses.
- The Streamlit application displays the results to the user.
To test this setup, we deployed this solution in an AWS account and analyzed Amazon earnings for the last 16 quarters. The results from a semantic search with default chunking vs. a hybrid search with fixed size chunking and maximum results are displayed in the following table.
| Question | Semantic Search with Default Chunking | Hybrid Search with Fixed Size Chunking |
| What is the change in total operating expenses for technology and infrastructure from 2020 to 2023? | Based on the information provided in the search results, I could not find the exact change in total operating expenses for technology and infrastructure from 2020 to 2023. The search results provide some financial data, but do not break down the operating expenses into specific categories like technology and infrastructure. Without that level of detail, I cannot determine the exact change in those expenses over that time period |
Based on the financial information provided, Amazon’s operating expenses for technology and infrastructure increased from 42.7billion in 2020 to 85.6 billion in 2023, an increase of $42.9 billion. |
| What are the international operating expenses in 2020, 2021 and 2022? | Based on the search results, I could not find any information about Amazon’s international operating expenses for the years 2020, 2021, and 2022. The financial information provided in the search results focuses on Amazon’s overall operating expenses, cash flows, and other financial metrics, but does not break down the expenses by international operations. |
The international operating expenses for Amazon were: 2020: 103,695 million 2021:128,711 million 2022: $125,753 million |
As seen in the results, the hybrid search option provides correct answers to all the questions.
Clean up
To prevent incurring costs after deploying and testing this solution, delete the S3 bucket, knowledge base, and CloudFormation stack.
Conclusion
In this post, we discussed how Amazon Bedrock Knowledge Bases provides a powerful solution that enables numerical analysis on documents. You can deploy this solution in an AWS account and use it to analyze different types of documents. As we continue to push the boundaries of generative AI, solutions like this will play a pivotal role in bridging the gap between unstructured data and actionable insights, enabling organizations to unlock the full potential of their data assets.
To further explore the advanced RAG capabilities of Amazon Bedrock Knowledge Bases, refer to the following resources:
About the Authors
 Sanjeev Pulapaka is a Principal Solutions architect and the Single Threaded Leader for AI/ML in the US federal civilian team at AWS. He advises customers on AI/ML-related solutions that advance their mission. Sanjeev has extensive experience in leading, architecting, and implementing high-impact technology solutions that address diverse business needs in multiple sectors, including commercial, federal, and state and local governments. He has an undergraduate degree in engineering from the Indian Institute of Technology and an MBA from the University of Notre Dame.
Sanjeev Pulapaka is a Principal Solutions architect and the Single Threaded Leader for AI/ML in the US federal civilian team at AWS. He advises customers on AI/ML-related solutions that advance their mission. Sanjeev has extensive experience in leading, architecting, and implementing high-impact technology solutions that address diverse business needs in multiple sectors, including commercial, federal, and state and local governments. He has an undergraduate degree in engineering from the Indian Institute of Technology and an MBA from the University of Notre Dame.
 Muhammad Qazafi is a Solutions Architect based in the US. He assists customers in designing, developing, and implementing secure, scalable, and innovative solutions on AWS. His objective is to help customers achieve measurable business outcomes through the effective utilization of AWS services. With over 15 years of experience, Muhammad brings a wealth of knowledge and expertise across a diverse range of industries. This extensive experience enables him to understand the unique challenges faced by different businesses and help customers create solutions on AWS.
Muhammad Qazafi is a Solutions Architect based in the US. He assists customers in designing, developing, and implementing secure, scalable, and innovative solutions on AWS. His objective is to help customers achieve measurable business outcomes through the effective utilization of AWS services. With over 15 years of experience, Muhammad brings a wealth of knowledge and expertise across a diverse range of industries. This extensive experience enables him to understand the unique challenges faced by different businesses and help customers create solutions on AWS.
 Venkata Kampana is a Senior Solutions architect in the AWS Health and Human Services team and is based in Sacramento, California. In this role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Venkata Kampana is a Senior Solutions architect in the AWS Health and Human Services team and is based in Sacramento, California. In this role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
[ad_2]



