
How to Run Stable Diffusion with ONNX | by Julia Turc | May, 2024
[ad_1]
Addressing compatibility issues during installation | ONNX for NVIDIA GPUs | Hugging Face’s Optimum library
This article discusses the ONNX runtime, one of the most effective ways of speeding up Stable Diffusion inference. On an A100 GPU, running SDXL for 30 denoising steps to generate a 1024 x 1024 image can be as fast as 2 seconds. However, the ONNX runtime depends on multiple moving pieces, and installing the right versions of all of its dependencies can be tricky in a constantly evolving ecosystem. Take this as a high-level debugging guide, where I share my struggles in hopes of saving you time. While the specific versions and commands might quickly become obsolete, the high-level concepts should remain relevant for a longer period of time.

ONNX can actually refer to two different (but related) parts of the ML stack:
- ONNX is a format for storing machine learning models. It stands for Open Neural Network Exchange and, as its name suggests, its main goal is interoperability across platforms. ONNX is a self-contained format: it stores both the model weights and architecture. This means that a single .onnx file contains all the information needed to run inference. No need to write any additional code to define or load a model; instead, you simply pass it to a runtime (more on this below).
- ONNX is also a runtime to run model that are in ONNX format. It literally runs the model. You can see it as a mediator between the architecture-agnostic ONNX format and the actual hardware that runs inference. There is a separate version of the runtime for each supported accelerator type (see full list here). Note, however, that the ONNX runtime is not the only way to run inference with a model that is in ONNX format — it’s just one way. Manufacturers can choose to build their own runtimes that are hyper-optimized for their hardware. For instance, NVIDIA’s TensorRT is an alternative to the ONNX runtime.
This article focuses on running Stable Diffusion models using the ONNX runtime. While the high-level concepts are probably timeless, note that the ML tooling ecosystem is in constant change, so the exact workflow or code snippets might become obsolete (this article was written in May 2024). I will focus on the Python implementation in particular, but note that the ONNX runtime can also operate in other languages like C++, C#, Java or JavaScript.
Pros of the ONNX Runtime
- Balance between inference speed and interoperability. While the ONNX runtime will not always be the fastest solution for all types of hardware, it is a fast enough solution for most types of hardware. This is particularly appealing if you’re serving your models on a heterogeneous fleet of machines and don’t have the resources to micro-optimize for each different accelerator.
- Wide adoption and reliable authorship. ONNX was open-sourced by Microsoft, who are still maintaining it. It is widely adopted and well integrated into the wider ML ecosystem. For instance, Hugging Face’s Optimum library allows you to define and run ONNX model pipelines with a syntax that is reminiscent of their popular transformers and diffusers libraries.
Cons of the ONNX Runtime
- Engineering overhead. Compared to the alternative of running inference directly in PyTorch, the ONNX runtime requires compiling your model to the ONNX format (which can take 20–30 minutes for a Stable Diffusion model) and installing the runtime itself.
- Restricted set of ops. The ONNX format doesn’t support all PyTorch operations (it is even more restrictive than TorchScript). If your model is using an unsupported operation, you will either have to reimplement the relevant portion, or drop ONNX altogether.
- Brittle installation and setup. Since the ONNX runtime makes the translation from the ONNX format to architecture-specific instructions, it can be tricky to get the right combination of software versions to make it work. For instance, if running on an NVIDIA GPU, you need to ensure compatibility of (1) operating system, (2) CUDA version, (3) cuDNN version, and (4) ONNX runtime version. There are useful resources like the CUDA compatibility matrix, but you might still end up wasting hours finding the magic combination that works at a given point in time.
- Hardware limitations. While the ONNX runtime can run on many architectures, it cannot run on all architectures like pure PyTorch models can. For instance, there is currently (May 2024) no support for Google Cloud TPUs or AWS Inferentia chips (see FAQ).
At first glance, the list of cons looks longer than the list of pros, but don’t be discouraged — as shown later on, the improvements in model latency can be significant and worth it.
Option #1: Install from source
As mentioned above, the ONNX runtime requires compatibility between many pieces of software. If you want to be on the cutting edge, the best way to get the latest version is to follow the instructions in the official Github repository. For Stable Diffusion in particular, this folder contains installation instructions and sample scripts for generating images. Expect building from source to take quite a while (around 30 minutes).
At the time of writing (May 2024), this solution worked seamlessly for me on an Amazon EC2 instance (g5.2xlarge, which comes with a A10G GPU). It avoids compatibility issues discussed below by using a Docker image that comes with the right dependencies.
Option #2: Install via PyPI
In production, you will most likely want a stable version of the ONNX runtime from PyPI, instead of installing the latest version from source. For Python in particular, there are two different libraries (one for CPU and one for GPU). Here is the command to install it for CPU:
pip install onnxruntime
And here is the command to install it for GPU:
pip install onnxruntime-gpu
You should never install both. Having them both might lead to error messages or behaviors that are not easy to track back to this root cause. The ONNX runtime might simply fail to acknowledge the presence of the GPU, which will look surprising given that onnxruntime-gpu is indeed installed.
In an ideal world, pip install onnxruntime-gpu would be the end of the story. However, in practice, there are strong compatibility requirements between other pieces of software on your machine, including the operating system, the hardware-specific drivers, and the Python version.
Say that you want to use the latest version of the ONNX runtime (1.17.1) at the time of writing. So what stars do we need to align to make this happen?
Here are some of the most common sources of incompatibility that can help you set up your environment. The exact details will quickly become obsolete, but the high-level ideas should continue to apply for a while.
CUDA compatibility
If you are not planning on using an NVIDIA GPU, you can skip this section. CUDA is a platform for parallel computing that sits on top of NVIDIA GPUs, and is required for machine learning workflows. Each version of the ONNX runtime is compatible with only certain CUDA versions, as you can see in this compatibility matrix.
According to this matrix, the latest ONNX runtime version (1.17) is compatible with both CUDA 11.8 and CUDA 12. But you need to pay attention to the fine print: by default, ONNX runtime 1.17 expects CUDA 11.8. However, most VMs today (May 2024) come with CUDA 12.1 (you can check the version by running nvcc --version). For this particular setup, you’ll have to replace the usual pip install onnxruntime-gpu with:
pip install onnxruntime-gpu==1.17.1 --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/
Note that, instead of being at the mercy of whatever CUDA version happens to be installed on your machine, a cleaner solution is to do your work from within a Docker container. You simply choose the image that has your desired version of Python and CUDA. For instance:
docker run --rm -it --gpus all nvcr.io/nvidia/pytorch:23.10-py3
OS + Python + pip compatibility
This section discusses compatibility issues that are architecture-agnostic (i.e. you’ll encounter them regardless of the target accelerator). It boils down to making sure that your software (operating system, Python installation and pip installation) are compatible with your desired version of the ONNX runtime library.
Pip version: Unless you are working with legacy code or systems, your safest bet is to upgrade pip to the latest version:
python -m pip install --upgrade pip
Python version: As of May 2024, the Python version that is least likely to give you headaches is 3.10 (this is what most VMs come with by default). Again, unless you are working with legacy code, you certainly want at least 3.8 (since 3.7 was deprecated in June 2023).
Operating system: The fact that the OS version can also hinder your ability to install the desired library came as a surprise to me, especially that I was using the most standard EC2 instances. And it wasn’t straightforward to figure out that the OS version was the culprit.
Here I will walk you through my debugging process, in the hopes that the workflow itself is longer-lived than the specifics of the versions today. First, I installed onnxruntime-gpu with the following command (since I had CUDA 12.1 installed on my machine):
pip install onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/
On the surface, this should install the latest version of the library available on PyPI. In reality however, this will install the latest version compatible with your current setup (OS + Python version + pip version). For me at the time, that happened to be onnxruntime-gpu==1.16.0. (as opposed to 1.17.1, which is the latest). Unknowingly installing an older version simply manifested in the ONNX runtime being unable to detect the GPU, with no other clues. After somewhat accidentally discovering the version is older than expected, I explicitly asked for the newer one:
pip install onnxruntime-gpu==1.17.1 --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/
This resulted in a message from pip complaining that the version I requested is not actually available (despite being listed on PyPI):
ERROR: Could not find a version that satisfies the requirement onnxruntime-gpu==1.17.1 (from versions: 1.12.0, 1.12.1, 1.13.1, 1.14.0, 1.14.1, 1.15.0, 1.15.1, 1.16.0, 1.16.1, 1.16.2, 1.16.3)
ERROR: No matching distribution found for onnxruntime-gpu==1.17.1
To understand why the latest version is not getting installed, you can pass a flag that makes pip verbose: pip install ... -vvv. This reveals all the Python wheels that pip cycles through in order to find the newest one that is compatible to your system. Here is what the output looked like for me:
Skipping link: none of the wheel's tags (cp35-cp35m-manylinux1_x86_64) are compatible (run pip debug --verbose to show compatible tags): https://files.pythonhosted.org/packages/26/1a/163521e075d2e0c3effab02ba11caba362c06360913d7c989dcf9506edb9/onnxruntime_gpu-0.1.2-cp35-cp35m-manylinux1_x86_64.whl (from https://pypi.org/simple/onnxruntime-gpu/)
Skipping link: none of the wheel's tags (cp36-cp36m-manylinux1_x86_64) are compatible (run pip debug --verbose to show compatible tags): https://files.pythonhosted.org/packages/52/f2/30aaa83bc9e90e8a919c8e44e1010796eb30f3f6b42a7141ffc89aba9a8e/onnxruntime_gpu-0.1.2-cp36-cp36m-manylinux1_x86_64.whl (from https://pypi.org/simple/onnxruntime-gpu/)
Skipping link: none of the wheel's tags (cp37-cp37m-manylinux1_x86_64) are compatible (run pip debug --verbose to show compatible tags): https://files.pythonhosted.org/packages/a2/05/af0481897255798ee57a242d3989427015a11a84f2eae92934627be78cb5/onnxruntime_gpu-0.1.2-cp37-cp37m-manylinux1_x86_64.whl (from https://pypi.org/simple/onnxruntime-gpu/)
Skipping link: none of the wheel's tags (cp35-cp35m-manylinux1_x86_64) are compatible (run pip debug --verbose to show compatible tags): https://files.pythonhosted.org/packages/17/cb/0def5a44db45c6d38d95387f20057905ce2dd4fad35c0d43ee4b1cebbb19/onnxruntime_gpu-0.1.3-cp35-cp35m-manylinux1_x86_64.whl (from https://pypi.org/simple/onnxruntime-gpu/)
Skipping link: none of the wheel's tags (cp36-cp36m-manylinux1_x86_64) are compatible (run pip debug --verbose to show compatible tags): https://files.pythonhosted.org/packages/a6/53/0e733ebd72d7dbc84e49eeece15af13ab38feb41167fb6c3e90c92f09cbb/onnxruntime_gpu-0.1.3-cp36-cp36m-manylinux1_x86_64.whl (from https://pypi.org/simple/onnxruntime-gpu/)
...
The tags listed in brackets are Python platform compatibility tags, and you can read more about them here. In a nutshell, every Python wheel comes with a tag that indicates what system it can run on. For instance, cp35-cp35m-manylinux1_x86_64 requires CPython 3.5, a set of (older) Linux distributions that fall under the manylinux1 umbrella, and a 64-bit x86-compatible processor.
Since I wanted to run Python 3.10 on a Linux machine (hence filtering for cp310.*manylinux.*, I was left with a single possible wheel for the onnxruntime-gpu library, with the following tag:
cp310-cp310-manylinux_2_28_x86_64
You can get a list of tags that are compatible with your system by running pip debug --verbose. Here is what part of my output looked like:
cp310-cp310-manylinux_2_26_x86_64
cp310-cp310-manylinux_2_25_x86_64
cp310-cp310-manylinux_2_24_x86_64
cp310-cp310-manylinux_2_23_x86_64
cp310-cp310-manylinux_2_22_x86_64
cp310-cp310-manylinux_2_21_x86_64
cp310-cp310-manylinux_2_20_x86_64
cp310-cp310-manylinux_2_19_x86_64
cp310-cp310-manylinux_2_18_x86_64
cp310-cp310-manylinux_2_17_x86_64
...
In other words, my operating system is just a tad too old (the maximum linux tag that it supports is manylinux_2_26, while the onnxruntime-gpu library’s only Python 3.10 wheel requires manylinux_2_28. Upgrading from Ubuntu 20.04 to Ubuntu 24.04 solved the problem.
Once the ONNX runtime is (finally) installed, generating images with Stable Diffusion requires two following steps:
- Export the PyTorch model to ONNX (this can take > 30 minutes!)
- Pass the ONNX model and the inputs (text prompt and other parameters) to the ONNX runtime.
Option #1: Using official scripts from Microsoft
As mentioned before, using the official sample scripts from the ONNX runtime repository worked out of the box for me. If you follow their installation instructions, you won’t even have to deal with the compatibility issues mentioned above. After installation, generating an image is a simple as:
python3 demo_txt2img_xl.py "starry night over Golden Gate Bridge by van gogh"
Under the hood, this script defines an SDXL model using Hugging Face’s diffusers library, exports it to ONNX format (which can take up to 30 minutes!), then invokes the ONNX runtime.
Option #2: Using Hugging Face’s Optimum library
The Optimum library promises a lot of convenience, allowing you to run models on various accelerators while using the familiar pipeline APIs from the well-known transformers and diffusers libraries. For ONNX in particular, this is what inference code for SDXL looks like (more in this tutorial):
from optimum.onnxruntime import ORTStableDiffusionXLPipelinemodel_id = "stabilityai/stable-diffusion-xl-base-1.0"
base = ORTStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Leonardo da Vinci"
image = base(prompt).images[0]
# Don't forget to save the ONNX model
save_directory = "sd_xl_base"
base.save_pretrained(save_directory)
In practice, however, I struggled a lot with the Optimum library. First, installation is non-trivial; naively following the installation instruction in the README file will run into the incompatibility issues explained above. This is not Optimum’s fault per se, but it does add yet another layer of abstraction on top of an already brittle setup. The Optimum installation might pull a version of onnxruntime that is conflicting with your setup.
Even after I won the battle against compatibility issues, I wasn’t able to run SDXL inference on GPU using Optimum’s ONNX interface. The code snippet above (directly taken from a Hugging Face tutorial) fails with some shape mismatches, perhaps due to bugs in the PyTorch → ONNX conversion:
[ONNXRuntimeError] : 1 : FAIL : Non-zero status code returned while running Add node.
Name:'/down_blocks.1/attentions.0/Add'
Status Message: /down_blocks.1/attentions.0/Add: left operand cannot broadcast on dim 3 LeftShape: {2,64,4096,10}, RightShape: {2,640,64,64}
For a brief second I considered getting into the weeds and debugging the Hugging Face code (at least it’s open source!), but gave up when I realized that Optimum has a backlog of more than 250 issues, with issues going for weeks with no acknowledgement from the Hugging Face team. I decided to move on and simply use Microsoft’s official scripts instead.
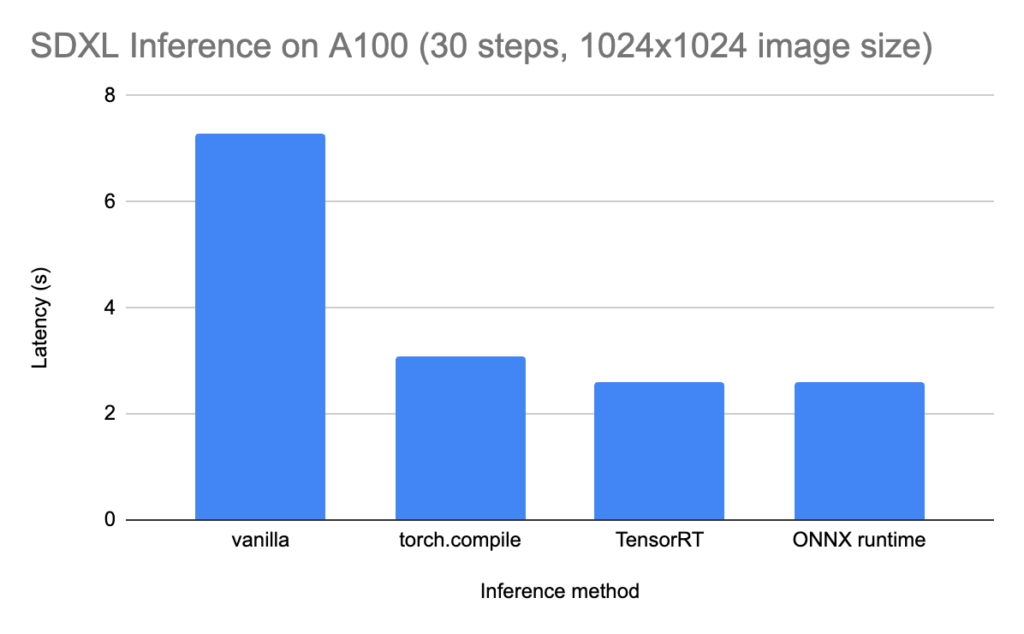
As promised, the effort to get the ONNX runtime working is worth it. On an A100 GPU, the inference time is reduced from 7–8 seconds (when running vanilla PyTorch) to ~2 seconds. This is comparable to TensorRT (an NVIDIA-specific alternative to ONNX), and about 1 second faster than torch.compile (PyTorch’s native JIT compilation).
Reportedly, switching to even more performant GPUs (e.g. H100) can lead to even higher gains from running your model with a specialized runtime.
The ONNX runtime promises significant latency gains, but it comes with non-trivial engineering overhead. It also faces the classic trade-off for static compilation: inference is a lot faster, but the graph cannot be dynamically modified (which is at odds with dynamic adapters like peft). The ONNX runtime and similar compilation methods are worth adding to your pipeline once you’ve passed the experimentation phase, and are ready to invest in efficient production code.
If you’re interested in optimizing inference time, here are some articles that I found helpful:
[ad_2]



