
LLM experimentation at scale using Amazon SageMaker Pipelines and MLflow
[ad_1]
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task. You can customize the model using prompt engineering, Retrieval Augmented Generation (RAG), or fine-tuning. Evaluation of a customized LLM against the base LLM (or other models) is necessary to make sure the customization process has improved the model’s performance on your specific task or dataset.
In this post, we dive into LLM customization using fine-tuning, exploring the key considerations for successful experimentation and how Amazon SageMaker with MLflow can simplify the process using Amazon SageMaker Pipelines.
LLM selection and fine-tuning journeys
When working with LLMs, customers often have different requirements. Some may be interested in evaluating and selecting the most suitable pre-trained foundation model (FM) for their use case, while others might need to fine-tune an existing model to adapt it to a specific task or domain. Let’s explore two customer journeys:

- Fine-tuning an LLM for a specific task or domain adaptation – In this user journey, you need to customize an LLM for a specific task or domain data. This requires fine-tuning the model. The fine-tuning process may involve one or more experiment, each requiring multiple iterations with different combinations of datasets, hyperparameters, prompts, and fine-tuning techniques, such as full or Parameter-Efficient Fine-Tuning (PEFT). Each iteration can be considered a run within an experiment.
Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. To simplify this process, you can use Amazon SageMaker with MLflow and SageMaker Pipelines for fine-tuning and evaluation at scale. In this post, we describe the step-by-step solution and provide the source code in the accompanying GitHub repository.
Solution overview
Running hundreds of experiments, comparing the results, and keeping a track of the ML lifecycle can become very complex. This is where MLflow can help streamline the ML lifecycle, from data preparation to model deployment. By integrating MLflow into your LLM workflow, you can efficiently manage experiment tracking, model versioning, and deployment, providing reproducibility. With MLflow, you can track and compare the performance of multiple LLM experiments, identify the best-performing models, and deploy them to production environments with confidence.
You can create workflows with SageMaker Pipelines that enable you to prepare data, fine-tune models, and evaluate model performance with simple Python code for each step.
Now you can use SageMaker managed MLflow to run LLM fine-tuning and evaluation experiments at scale. Specifically:
- MLflow can manage tracking of fine-tuning experiments, comparing evaluation results of different runs, model versioning, deployment, and configuration (such as data and hyperparameters)
- SageMaker Pipelines can orchestrate multiple experiments based on the experiment configuration
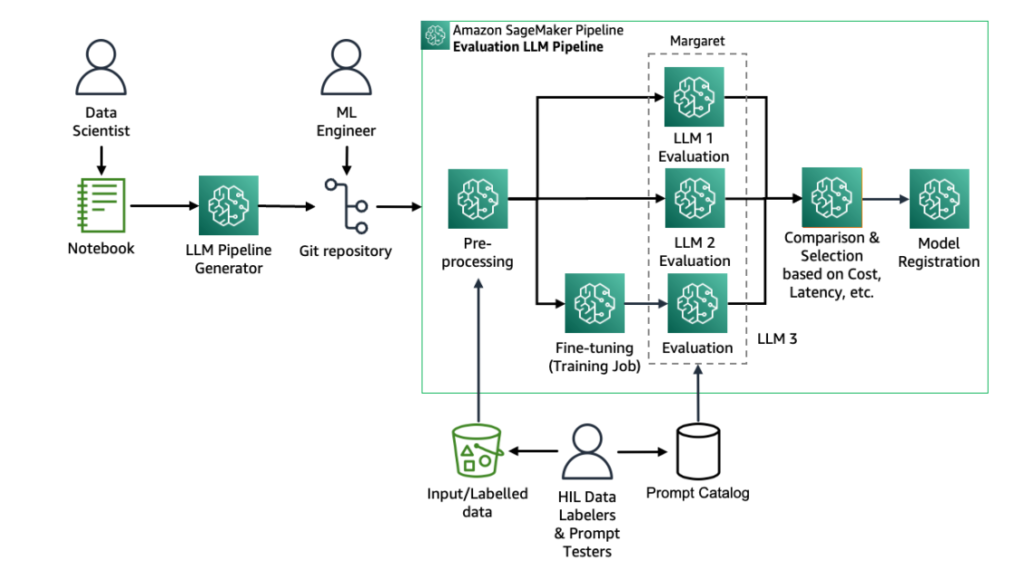
The following figure shows the overview of the solution.

Prerequisites
Before you begin, make sure you have the following prerequisites in place:
- Hugging Face login token – You need a Hugging Face login token to access the models and datasets used in this post. For instructions to generate a token, see User access tokens.
- SageMaker access with required IAM permissions – You need to have access to SageMaker with the necessary AWS Identity and Access Management (IAM) permissions to create and manage resources. Make sure you have the required permissions to create notebooks, deploy models, and perform other tasks outlined in this post. To get started, see Quick setup to Amazon SageMaker. Please follow this post to make sure you have proper IAM role confugured for MLflow.
Set up an MLflow tracking server
MLflow is directly integrated in Amazon SageMaker Studio. To create an MLflow tracking server to track experiments and runs, complete the following steps:
- On the SageMaker Studio console, choose MLflow under Applications in the navigation pane.

- For Name, enter an appropriate server name.
- For Artifact storage location (S3 URI), enter the location of an Amazon Simple Storage Service (Amazon S3) bucket.
- Choose Create.

The tracking server may require up to 20 minutes to initialize and become operational. When it’s running, you can note its ARN to use in the llm_fine_tuning_experiments_mlflow.ipynb notebook. The ARN will have the following format:
For subsequent steps, you can refer to the detailed description provided in this post, as well as the step-by-step instructions outlined in the llm_fine_tuning_experiments_mlflow.ipynb notebook. You can Launch the notebook in Amazon SageMaker Studio Classic or SageMaker JupyterLab.
Overview of SageMaker Pipelines for experimentation at scale
We use SageMaker Pipelines to orchestrate LLM fine-tuning and evaluation experiments. With SageMaker Pipelines, you can:
- Run multiple LLM experiment iterations simultaneously, reducing overall processing time and cost
- Effortlessly scale up or down based on changing workload demands
- Monitor and visualize the performance of each experiment run with MLflow integration
- Invoke downstream workflows for further analysis, deployment, or model selection
MLflow integration with SageMaker Pipelines requires the tracking server ARN. You also need to add the mlflow and sagemaker-mlflow Python packages as dependencies in the pipeline setup. Then you can use MLflow in any pipeline step with the following code snippet:
Log datasets with MLflow
With MLflow, you can log your dataset information alongside other key metrics, such as hyperparameters and model evaluation. This enables tracking and reproducibility of experiments across different runs, allowing for more informed decision-making about which models perform best on specific tasks or domains. By logging your datasets with MLflow, you can store metadata, such as dataset descriptions, version numbers, and data statistics, alongside your MLflow runs.
In the preproccess step, you can log training data and evaluation data. In this example, we download the data from a Hugging Face dataset. We are using HuggingFaceH4/no_robots for fine-tuning and evaluation. First, you need to set the MLflow tracking ARN and experiment name to log data. After you process the data and select the required number of rows, you can log the data using the log_input API of MLflow. See the following code:
Fine-tune a Llama model with LoRA and MLflow
To streamline the process of fine-tuning LLM with Low-Rank Adaption (LoRA), you can use MLflow to track hyperparameters and save the resulting model. You can experiment with different LoRA parameters for training and log these parameters along with other key metrics, such as training loss and evaluation metrics. This enables tracking of your fine-tuning process, allowing you to identify the most effective LoRA parameters for a given dataset and task.
For this example, we use the PEFT library from Hugging Face to fine-tune a Llama 3 model. With this library, we can perform LoRA fine-tuning, which offers faster training with reduced memory requirements. It can also work well with less training data.
We use the HuggingFace class from the SageMaker SDK to create a training step in SageMaker Pipelines. The actual implementation of training is defined in llama3_fine_tuning.py. Just like the previous step, we need to set the MLflow tracking URI and use the same run_id:
While using the Trainer class from Transformers, you can mention where you want to report the training arguments. In our case, we want to log all the training arguments to MLflow:
When the training is complete, you can save the full model, so you need to merge the adapter weights to the base model:
The merged model can be logged to MLflow with the model signature, which defines the expected format for model inputs and outputs, including any additional parameters needed for inference:
Evaluate the model
Model evaluation is the key step to select the most optimal training arguments for fine-tuning the LLM for a given dataset. In this example, we use the built-in evaluation capability of MLflow with the mlflow.evaluate() API. For question answering models, we use the default evaluator logs exact_match, token_count, toxicity, flesch_kincaid_grade_level, and ari_grade_level.
MLflow can load the model that was logged in the fine-tuning step. The base model is downloaded from Hugging Face and adapter weights are downloaded from the logged model. See the following code:
These evaluation results are logged in MLflow in the same run that logged the data processing and fine-tuning step.
Create the pipeline
After you have the code ready for all the steps, you can create the pipeline:
You can run the pipeline using the SageMaker Studio UI or using the following code snippet in the notebook:
Compare experiment results
After you start the pipeline, you can track the experiment in MLflow. Each run will log details of the preprocessing, fine-tuning, and evaluation steps. The preprocessing step will log training and evaluation data, and the fine-tuning step will log all training arguments and LoRA parameters. You can select these experiments and compare the results to find the optimal training parameters and best fine-tuned model.
You can open the MLflow UI from SageMaker Studio.

Then you can select the experiment to filter out runs for that experiment. You can select multiple runs to make the comparison.

When you compare, you can analyze the evaluation score against the training arguments.

Register the model
After you analyze the evaluation results of different fine-tuned models, you can select the best model and register it in MLflow. This model will be automatically synced with Amazon SageMaker Model Registry.


Deploy the model
You can deploy the model through the SageMaker console or SageMaker SDK. You can pull the model artifact from MLflow and use the ModelBuilder class to deploy the model:
Clean up
In order to not incur ongoing costs, delete the resources you created as part of this post:
- Delete the MLflow tracking server.
- Run the last cell in the notebook to delete the SageMaker pipeline:
Conclusion
In this post, we focused on how to run LLM fine-tuning and evaluation experiments at scale using SageMaker Pipelines and MLflow. You can use managed MLflow from SageMaker to compare training parameters and evaluation results to select the best model and deploy that model in SageMaker. We also provided sample code in a GitHub repository that shows the fine-tuning, evaluation, and deployment workflow for a Llama3 model.
You can start taking advantage of SageMaker with MLflow for traditional MLOps or to run LLM experimentation at scale.
About the Authors
 Jagdeep Singh Soni is a Senior Partner Solutions Architect at AWS based in the Netherlands. He uses his passion for Generative AI to help customers and partners build GenAI applications using AWS services. Jagdeep has 15 years of experience in innovation, experience engineering, digital transformation, cloud architecture and ML applications.
Jagdeep Singh Soni is a Senior Partner Solutions Architect at AWS based in the Netherlands. He uses his passion for Generative AI to help customers and partners build GenAI applications using AWS services. Jagdeep has 15 years of experience in innovation, experience engineering, digital transformation, cloud architecture and ML applications.
 Dr. Sokratis Kartakis is a Principal Machine Learning and Operations Specialist Solutions Architect for Amazon Web Services. Sokratis focuses on enabling enterprise customers to industrialize their ML and generative AI solutions by exploiting AWS services and shaping their operating model, such as MLOps/FMOps/LLMOps foundations, and transformation roadmap using best development practices. He has spent over 15 years inventing, designing, leading, and implementing innovative end-to-end production-level ML and AI solutions in the domains of energy, retail, health, finance, motorsports, and more.
Dr. Sokratis Kartakis is a Principal Machine Learning and Operations Specialist Solutions Architect for Amazon Web Services. Sokratis focuses on enabling enterprise customers to industrialize their ML and generative AI solutions by exploiting AWS services and shaping their operating model, such as MLOps/FMOps/LLMOps foundations, and transformation roadmap using best development practices. He has spent over 15 years inventing, designing, leading, and implementing innovative end-to-end production-level ML and AI solutions in the domains of energy, retail, health, finance, motorsports, and more.
 Kirit Thadaka is a Senior Product Manager at AWS focused on generative AI experimentation on Amazon SageMaker. Kirit has extensive experience working with customers to build scalable workflows for MLOps to make them more efficient at bringing models to production.
Kirit Thadaka is a Senior Product Manager at AWS focused on generative AI experimentation on Amazon SageMaker. Kirit has extensive experience working with customers to build scalable workflows for MLOps to make them more efficient at bringing models to production.
 Piyush Kadam is a Senior Product Manager for Amazon SageMaker, a fully managed service for generative AI builders. Piyush has extensive experience delivering products that help startups and enterprise customers harness the power of foundation models.
Piyush Kadam is a Senior Product Manager for Amazon SageMaker, a fully managed service for generative AI builders. Piyush has extensive experience delivering products that help startups and enterprise customers harness the power of foundation models.
[ad_2]



