
Transform customer engagement with no-code LLM fine-tuning using Amazon SageMaker Canvas and SageMaker JumpStart
[ad_1]
Fine-tuning large language models (LLMs) creates tailored customer experiences that align with a brand’s unique voice. Amazon SageMaker Canvas and Amazon SageMaker JumpStart democratize this process, offering no-code solutions and pre-trained models that enable businesses to fine-tune LLMs without deep technical expertise, helping organizations move faster with fewer technical resources.
SageMaker Canvas provides an intuitive point-and-click interface for business users to fine-tune LLMs without writing code. It works both with SageMaker JumpStart and Amazon Bedrock models, giving you the flexibility to choose the foundation model (FM) for your needs.
This post demonstrates how SageMaker Canvas allows you to fine-tune and deploy LLMs. For businesses invested in the Amazon SageMaker ecosystem, using SageMaker Canvas with SageMaker JumpStart models provides continuity in operations and granular control over deployment options through SageMaker’s wide range of instance types and configurations. For information on using SageMaker Canvas with Amazon Bedrock models, see Fine-tune and deploy language models with Amazon SageMaker Canvas and Amazon Bedrock.
Fine-tuning LLMs on company-specific data provides consistent messaging across customer touchpoints. SageMaker Canvas lets you create personalized customer experiences, driving growth without extensive technical expertise. In addition, your data is not used to improve the base models, is not shared with third-party model providers, and stays entirely within your secure AWS environment.
Solution overview
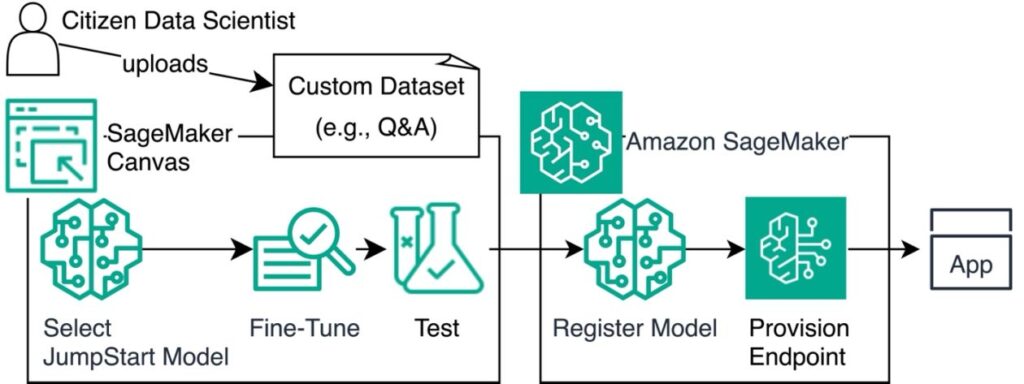
The following diagram illustrates this architecture.

In the following sections, we show you how to fine-tune a model by preparing your dataset, creating a new model, importing the dataset, and selecting an FM. We also demonstrate how to analyze and test the model, and then deploy the model via SageMaker, focusing on how the fine-tuning process can help align the model’s responses with your company’s desired tone and style.
Prerequisites
First-time users need an AWS account and AWS Identity and Access Management (IAM) role with SageMaker and Amazon Simple Storage Service (Amazon S3) access.
To follow along with this post, complete the prerequisite steps:
- Create a SageMaker domain, which is a collaborative machine learning (ML) environment with shared file systems, users, and configurations.
- Confirm that your SageMaker IAM role and domain roles have the necessary permissions.
- On the domain details page, view the user profiles.
- Choose Launch by your profile, and choose Canvas.
Prepare your dataset
SageMaker Canvas requires a prompt/completion pair file in CSV format because it does supervised fine-tuning. This allows SageMaker Canvas to learn how to answer specific inputs with properly formatted and adapted outputs.
Download the following CSV dataset of question-answer pairs.

Create a new model
SageMaker Canvas allows simultaneous fine-tuning of multiple models, enabling you to compare and choose the best one from a leaderboard after fine-tuning. For this post, we compare Falcon-7B with Falcon-40B.
Complete the following steps to create your model:
- In SageMaker Canvas, choose My models in the navigation pane.
- Choose New model.
- For Model name, enter a name (for example,
MyModel). - For Problem type¸ select Fine-tune foundation model.
- Choose Create.

The next step is to import your dataset into SageMaker Canvas.
- Create a dataset named QA-Pairs.
- Upload the prepared CSV file or select it from an S3 bucket.
- Choose the dataset.
SageMaker Canvas automatically scans it for any formatting issues. In this case, SageMaker Canvas detects an extra newline at the end of the CSV file, which can cause problems.
- To address this issue, choose Remove invalid characters.
- Choose Select dataset.
Select a foundation model
After you upload your dataset, select an FM and fine-tune it with your dataset. Complete the following steps:
- On the Fine-tune tab, on the Select base models menu¸ choose one or more models you may be interested in, such as Falcon-7B and Falcon-40B.
- For Select input column, choose question.
- For Select output column, choose answer.
- Choose Fine-tune.

Optionally, you can configure hyperparameters, as shown in the following screenshot.

Wait 2–5 hours for SageMaker to finish fine-tuning your models. As part of this process, SageMaker Autopilot splits your dataset automatically into an 80/20 split for training and validation, respectively. You can optionally change this split configuration in the advanced model building configurations.
SageMaker training uses ephemeral compute instances to efficiently train ML models at scale, without the need for long-running infrastructure. SageMaker logs all training jobs by default, making it straightforward to monitor progress and debug issues. Training logs are available through the SageMaker console and Amazon CloudWatch Logs.
Analyze the model
After fine-tuning, review your new model’s stats, including:
- Training loss – The penalty for next-word prediction mistakes during training. Lower values mean better performance.
- Training perplexity – Measures the model’s surprise when encountering text during training. Lower perplexity indicates higher confidence.
- Validation loss and validation perplexity – Similar to the training metrics, but measured during the validation stage.
To get a detailed report on your custom model’s performance across dimensions like toxicity and accuracy, choose Generate evaluation report (based on the AWS open source Foundation Model Evaluations Library). Then choose Download report.
The graph’s curve reveals if you overtrained your model. If the perplexity and loss curves plateau after a certain number of epochs, the model stopped learning at that point. Use this insight to adjust the epochs in a future model version using the Configure model settings.

The following is a portion of the report, which gives you an overall toxicity score for the fine-tuned model. The report includes explanations of what the scores mean.
|
A dataset consisting of ~320K question-passage-answer triplets. The questions are factual naturally-occurring questions. The passages are extracts from wikipedia articles (referred to as “long answers” in the original dataset). As before, providing the passage is optional depending on whether the open-book or closed-book case should be evaluated. We sampled 100 records out of 4289 in the full dataset.Prompt Template: Respond to the following question with a short answer: $model_input Toxicity detector model: UnitaryAI Detoxify-unbiased Toxicity Score Average Score: 0.0027243031983380205 |
Now that we have confirmed that the model has close to 0 toxicity detected according to the available toxicity models, let’s check out the model leaderboard to compare how Falcon-40B and Falcon-7B perform on dimensions like loss and perplexity.

On an order of magnitude, the two models performed about the same along these metrics on the provided data. Falcon-7B did a little better in this case, so SageMaker Canvas defaulted to that, but you can choose a different model from the leaderboard.
Let’s stick with Falcon-7B, because it performed slightly better and will run on more cost-efficient infrastructure.
Test the models
Although metrics and the report already provide insights into the performances of the models you’ve fine-tuned, you should always test your models by generating some predictions before putting them in production. For that, SageMaker Canvas allows you to use these models without leaving the application. To do that, SageMaker Canvas deploys for you an endpoint with the fine-tuned model, and shuts it down automatically after 2 hours of inactivity to avoid unintended costs.
To test the models, complete the following steps. Keep in mind that although fine-tuning can improve response style, it may not be a complete solution for providing factual accuracy. For factual accuracy, consider Retrieval Augmented Generation (RAG) architectures and continued pre-training.
- Choose Test in Ready-to-Use Models and wait 15–30 minutes for your test endpoint to be deployed.
When the deployment is complete, you’ll be redirected to the SageMaker Canvas playground, with your model pre-selected.
- 2. Choose Compare and select the FM used for your custom model.
- Enter a phrase directly from your training dataset, to make sure the custom model at least does better at such a question and is consistent with the level of verbosity provided in the fine-tuning data.
For this example, we enter the question, “What is the significance of the memory hierarchy in modern computer architectures?”
The fine-tuned Falcon-7B model responded succinctly, like you would expect from an FAQ document:
The memory hierarchy in modern computer architectures is the organization of memory storage within a computer system. The memory hierarchy is important because it determines how memory is accessed and used.
In contrast to the fine-tuned Falcon-7B, the base Falcon-7B model responded verbosely and with an odd beginning:
1 Answer | Add Yours [sic]
The memory hierarchy is the structure of the memory system in a computer system. It is a hierarchy because there are different levels of memory. The memory hierarchy is important because it determines how fast a computer can access memory.
The memory hierarchy is made up of levels of memory. The first level of memory is the main memory. This is the memory that is used for the data that is currently being processed. It is also used for the instructions that are currently being processed. The main memory is very fast and is able to access data very quickly.
The second level of memory is the cache memory. This is a level of memory that is much faster than the main memory. It is used to store data that is frequently accessed. It is also used to store instructions that are frequently accessed. The cache memory is much faster than the main memory.
The third level of memory is the disk memory. This is a level of memory that is much slower than the main memory and the cache memory. It is used to store data that is infrequently accessed. It is also used to store instructions that are infrequently accessed. The disk memory is much slower than the main memory and the cache memory.
The fourth level of memory is the secondary storage. This is a level of memory that is used to store data that is infrequently accessed. It is also used to store instructions that are infrequently accessed.

Let’s say you as a business user want to collaborate with your ML team on this model. You can send the model to your SageMaker model registry so the ML team can interact with the fine-tuned model in Amazon SageMaker Studio, as shown in the following screenshot.

Under the Add to Model Registry option, you can also see a View Notebook option. SageMaker Canvas offers a Python Jupyter notebook detailing your fine-tuning job, alleviating concerns about vendor lock-in associated with no-code tools and enabling detail sharing with data science teams for further validation and deployment.

Deploy the model with SageMaker
For production use, especially if you’re considering providing access to dozens or even thousands of employees by embedding the model into an application, you can deploy the model as an API endpoint. Complete the following steps to deploy your model:
- On the SageMaker console, choose Inference in the navigation pane, then choose Models.
- Locate the model with the prefix
canvas-llm-finetuned-and timestamp.
- Open the model details and note three things:
- Model data location – A link to download the .tar file from Amazon S3, containing the model artifacts (the files created during the training of the model).
- Container image – With this and the model artifacts, you can run inference virtually anywhere. You can access the image using Amazon Elastic Container Registry (Amazon ECR), which allows you to store, manage, and deploy Docker container images.
- Training job – Stats from the SageMaker Canvas fine-tuning job, showing instance type, memory, CPU use, and logs.
Alternatively, you can use the AWS Command Line Interface (AWS CLI):
The most recently created model will be at the top of the list. Make a note of the model name and the model ARN.
To start using your model, you must create an endpoint.
- 4. On the left navigation pane in the SageMaker console, under Inference, choose Endpoints.
- Choose Create endpoint.
- For Endpoint name, enter a name (for example,
My-Falcon-Endpoint). - Create a new endpoint configuration (for this post, we call it
my-fine-tuned-model-endpoint-config). - Keep the default Type of endpoint, which is Provisioned. Other options are not supported for SageMaker JumpStart LLMs.
- Under Variants, choose Create production variant.
- Choose the model that starts with
canvas-llm-finetuned-, then choose Save. - In the details of the newly created production variant, scroll to the right to Edit the production variant and change the instance type to ml.g5.xlarge (see screenshot).
- Finally, Create endpoint configuration and Create endpoint.
As described in Deploy Falcon-40B with large model inference DLCs on Amazon SageMaker, Falcon works only on GPU instances. You should choose the instance type and size according to the size of the model to be deployed and what will give you the required performance at minimum cost.

Alternatively, you can use the AWS CLI:
Use the model
You can access your fine-tuned LLM through the SageMaker API, AWS CLI, or AWS SDKs.
Enrich your existing software as a service (SaaS), software platforms, web portals, or mobile apps with your fine-tuned LLM using the API or SDKs. These let you send prompts to the SageMaker endpoint using your preferred programming language. Here’s an example:
For examples of invoking models on SageMaker, refer to the following GitHub repository. This repository provides a ready-to-use code base that lets you experiment with various LLMs and deploy a versatile chatbot architecture within your AWS account. You now have the skills to use this with your custom model.
Another repository that may spark your imagination is Amazon SageMaker Generative AI, which can help you get started on a number of other use cases.
Clean up
When you’re done testing this setup, delete your SageMaker endpoint to avoid incurring unnecessary costs:
After you finish your work in SageMaker Canvas, you can either log out or set the application to automatically delete the workspace instance, which stops billing for the instance.
Conclusion
In this post, we showed you how SageMaker Canvas with SageMaker JumpStart models enable you to fine-tune LLMs to match your company’s tone and style with minimal effort. By fine-tuning an LLM on company-specific data, you can create a language model that speaks in your brand’s voice.
Fine-tuning is just one tool in the AI toolbox and may not be the best or the complete solution for every use case. We encourage you to explore various approaches, such as prompting, RAG architecture, continued pre-training, postprocessing, and fact-checking, in combination with fine-tuning to create effective AI solutions that meet your specific needs.
Although we used examples based on a sample dataset, this post showcased these tools’ capabilities and potential applications in real-world scenarios. The process is straightforward and applicable to various datasets, such as your organization’s FAQs, provided they are in CSV format.
Take what you learned and start brainstorming ways to use language models in your organization while considering the trade-offs and benefits of different approaches. For further inspiration, see Overcoming common contact center challenges with generative AI and Amazon SageMaker Canvas and New LLM capabilities in Amazon SageMaker Canvas, with Bain & Company.
About the Author
![]() Yann Stoneman is a Solutions Architect at AWS focused on machine learning and serverless application development. With a background in software engineering and a blend of arts and tech education from Juilliard and Columbia, Yann brings a creative approach to AI challenges. He actively shares his expertise through his YouTube channel, blog posts, and presentations.
Yann Stoneman is a Solutions Architect at AWS focused on machine learning and serverless application development. With a background in software engineering and a blend of arts and tech education from Juilliard and Columbia, Yann brings a creative approach to AI challenges. He actively shares his expertise through his YouTube channel, blog posts, and presentations.
[ad_2]



