
Unveiling the Inner Workings of LLMs: A Singular Value Perspective | by Louis Owen | Jun, 2024
[ad_1]
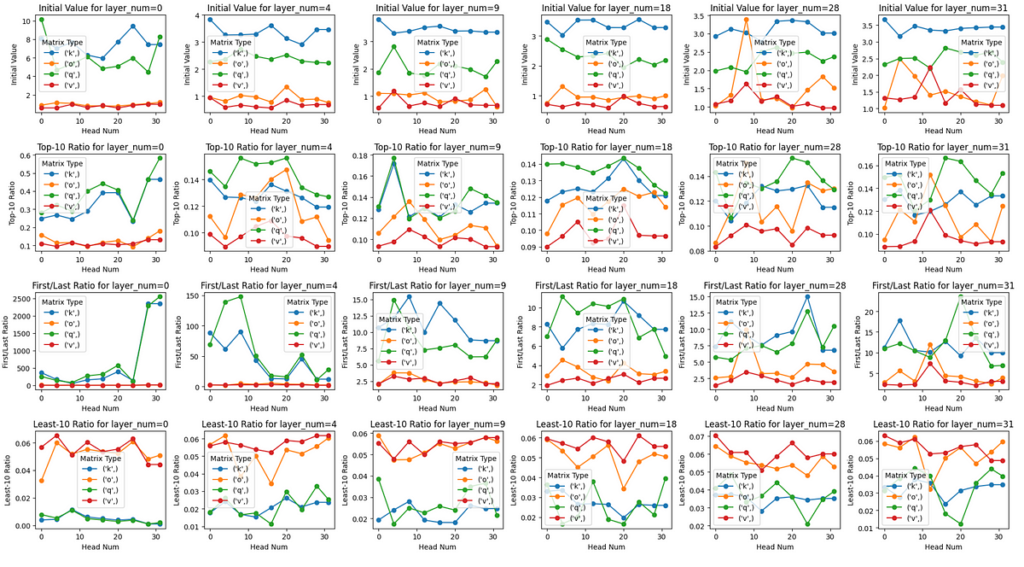
Now, let’s jump into the real deal of this article. Analyzing (Q, K, V, O) matrices of Llama-3–8B-Instruct model via their singular values!
The Code
Let’s first import all necessary packages needed in this analysis.
import transformers
import torch
import numpy as np
from transformers import AutoConfig, LlamaModel
from safetensors import safe_open
import os
import matplotlib.pyplot as plt
Then, let’s download the model and save it into our local /tmpdirectory.
MODEL_ID = "meta-llama/Meta-Llama-3-8B-Instruct"
!huggingface-cli download {MODEL_ID} --quiet --local-dir /tmp/{MODEL_ID}
If you’re GPU-rich, the following code might not be relevant for you. However, if you’re GPU-poor like me, the following code will be really useful to load only specific layers of the LLama-3–8B model.
def load_specific_layers_safetensors(model, model_name, layer_to_load):
state_dict = {}
files = [f for f in os.listdir(model_name) if f.endswith('.safetensors')]
for file in files:
filepath = os.path.join(model_name, file)
with safe_open(filepath, framework="pt") as f:
for key in f.keys():
if f"layers.{layer_to_load}." in key:
new_key = key.replace(f"model.layers.{layer_to_load}.", 'layers.0.')
state_dict[new_key] = f.get_tensor(key)missing_keys, unexpected_keys = model.load_state_dict(state_dict, strict=False)
if missing_keys:
print(f"Missing keys: {missing_keys}")
if unexpected_keys:
print(f"Unexpected keys: {unexpected_keys}")
The reason we do this is because the free tier of Google Colab GPU is not enough to load LLama-3–8B even with fp16 precision. Furthermore, this analysis requires us to work on fp32 precision due to how the np.linalg.svd is built. Next, we can define the main function to get singular values for a given matrix_type , layer_number , and head_number.
def get_singular_values(model_path, matrix_type, layer_number, head_number):
"""
Computes the singular values of the specified matrix in the Llama-3 model.Parameters:
model_path (str): Path to the model
matrix_type (str): Type of matrix ('q', 'k', 'v', 'o')
layer_number (int): Layer number (0 to 31)
head_number (int): Head number (0 to 31)
Returns:
np.array: Array of singular values
"""
assert matrix_type in ['q', 'k', 'v', 'o'], "Invalid matrix type"
assert 0 <= layer_number < 32, "Invalid layer number"
assert 0 <= head_number < 32, "Invalid head number"
# Load the model only for that specific layer since we have limited RAM even after using fp16
config = AutoConfig.from_pretrained(model_path)
config.num_hidden_layers = 1
model = LlamaModel(config)
load_specific_layers_safetensors(model, model_path, layer_number)
# Access the specified layer
# Always index 0 since we have loaded for the specific layer
layer = model.layers[0]
# Determine the size of each head
num_heads = layer.self_attn.num_heads
head_dim = layer.self_attn.head_dim
# Access the specified matrix
weight_matrix = getattr(layer.self_attn, f"{matrix_type}_proj").weight.detach().numpy()
if matrix_type in ['q','o']:
start = head_number * head_dim
end = (head_number + 1) * head_dim
else: # 'k', 'v' matrices
# Adjust the head_number based on num_key_value_heads
# This is done since llama3-8b use Grouped Query Attention
num_key_value_groups = num_heads // config.num_key_value_heads
head_number_kv = head_number // num_key_value_groups
start = head_number_kv * head_dim
end = (head_number_kv + 1) * head_dim
# Extract the weights for the specified head
if matrix_type in ['q', 'k', 'v']:
weight_matrix = weight_matrix[start:end, :]
else: # 'o' matrix
weight_matrix = weight_matrix[:, start:end]
# Compute singular values
singular_values = np.linalg.svd(weight_matrix, compute_uv=False)
del model, config
return list(singular_values)
It is worth noting that we can extract the weights for the specified head on the K, Q, and V matrices by doing row-wise slicing because of how it is implemented by HuggingFace.

(d_out,d_in). Source: Image by Author.As for the O matrix, we can do column-wise slicing to extract the weights for the specified head on the O weight thanks to linear algebra! Details can be seen in the following figure.

[ad_2]



