
Duplicate Detection with GenAI. How using LLMs and GenAI techniques can… | by Ian Ormesher | Jul, 2024
[ad_1]
How using LLMs and GenAI techniques can improve de-duplication

Customer data is often stored as records in Customer Relations Management systems (CRMs). Data which is manually entered into such systems by one of more users over time leads to data replication, partial duplication or fuzzy duplication. This in turn means that there no longer a single source of truth for customers, contacts, accounts, etc. Downstream business processes become increasing complex and contrived without a unique mapping between a record in a CRM and the target customer. Current methods to detect and de-duplicate records use traditional Natural Language Processing techniques known as Entity Matching. But it is possible to use the latest advancements in Large Language Models and Generative AI to vastly improve the identification and repair of duplicated records. On common benchmark datasets I found an improvement in the accuracy of data de-duplication rates from 30 percent using NLP techniques to almost 60 percent using my proposed method.
I want to explain the technique here in the hope that others will find it helpful and use it for their own de-duplication needs. It’s useful for other scenarios where you wish to identify duplicate records, not just for Customer data. I also wrote and published a research paper about this which you can view on Arxiv, if you want to know more in depth:
The task of identifying duplicate records is often done by pairwise record comparisons and is referred to as “Entity Matching” (EM). Typical steps of this process would be:
- Data Preparation
- Candidate Generation
- Blocking
- Matching
- Clustering
Data Preparation
Data preparation is the cleaning of the data and involves such things as removing non-ASCII characters, capitalisation and tokenising the text. This is an important and necessary step for the NLP matching algorithms later in the process which don’t work well with different cases or non-ASCII characters.
Candidate Generation
In the usual EM method, we would produce candidate records by combining all the records in the table with themselves to produce a cartesian product. You would remove all combinations which are of a row with itself. For a lot of the NLP matching algorithms comparing row A with row B is equivalent to comparing row B with row A. For those cases you can get away with keeping just one of those pairs. But even after this, you’re still left with a lot of candidate records. In order to reduce this number a technique called “blocking” is often used.
Blocking
The idea of blocking is to eliminate those records that we know could not be duplicates of each other because they have different values for the “blocked” column. As an example, If we were considering customer records, a potential column to block on could be something like “City”. This is because we know that even if all the other details of the record are similar enough, they cannot be the same customer if they’re located in different cities. Once we have generated our candidate records, we then use blocking to eliminate those records that have different values for the blocked column.
Matching
Following on from blocking we now examine all the candidate records and calculate traditional NLP similarity-based attribute value metrics with the fields from the two rows. Using these metrics, we can determine if we have a potential match or un-match.
Clustering
Now that we have a list of candidate records that match, we can then group them into clusters.
There are several steps to the proposed method, but the most important thing to note is that we no longer need to perform the “Data Preparation” or “Candidate Generation” step of the traditional methods. The new steps become:
- Create Match Sentences
- Create Embedding Vectors of those Match Sentences
- Clustering
Create Match Sentences
First a “Match Sentence” is created by concatenating the attributes we are interested in and separating them with spaces. As an example, let’s say we have a customer record which looks like this:
We would create a “Match Sentence” by concatenating with spaces the name1, name2, name3, address and city attributes which would give us the following:
“John Hartley Smith 20 Main Street London”
Create Embedding Vectors
Once our “Match Sentence” has been created it is then encoded into vector space using our chosen embedding model. This is achieved by using “Sentence Transformers”. The output of this encoding will be a floating-point vector of pre-defined dimensions. These dimensions relate to the embedding model that is used. I used the all-mpnet-base-v2 embedding model which has a vector space of 768 dimensions. This embedding vector is then appended to the record. This is done for all the records.
Clustering
Once embedding vectors have been calculated for all the records, the next step is to create clusters of similar records. To do this I use the DBSCAN technique. DBSCAN works by first selecting a random record and finding records that are close to it using a distance metric. There are 2 different kinds of distance metrics that I’ve found to work:
- L2 Norm distance
- Cosine Similarity
For each of those metrics you choose an epsilon value as a threshold value. All records that are within the epsilon distance and have the same value for the “blocked” column are then added to this cluster. Once that cluster is complete another random record is selected from the unvisited records and a cluster then created around it. This then continues until all the records have been visited.
I used this approach to identify duplicate records with customer data in my work. It produced some very nice matches. In order to be more objective, I also ran some experiments using a benchmark dataset called “Musicbrainz 200K”. It produced some quantifiable results that were an improvement over standard NLP techniques.
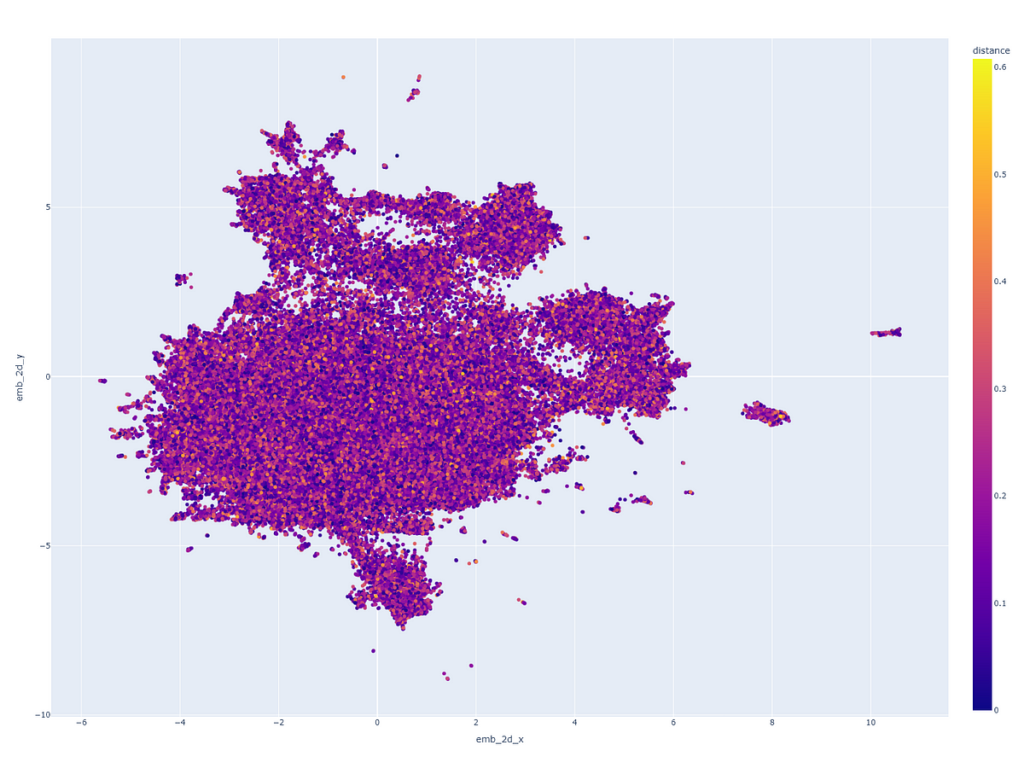
Visualising Clustering
I produced a nearest neighbour cluster map for the Musicbrainz 200K dataset which I then rendered in 2D using the UMAP reduction algorithm:
Resources
I have created various notebooks that will help with trying the method out for yourselves:
[ad_2]



